全人类最易懂的人工智能(机器学习)深度学习教程----第6集:CNN卷积神经网络and代码Pytorch实现(MNIST手写数字)(“看不懂CNN吗?看我!”)

学习机器学习一定要对着代码看(先放着,方便萌新找):
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential( # input shape (1, 28, 28)
nn.Conv2d(
in_channels=1, # input height
out_channels=16, # n_filters
kernel_size=5, # filter size
stride=1, # filter movement/step
padding=2, # if want same width and length of this image after Conv2d, padding=(kernel_size-1)/2 if stride=1
), # output shape (16, 28, 28)
nn.ReLU(), # activation
nn.MaxPool2d(kernel_size=2), # choose max value in 2x2 area, output shape (16, 14, 14)
)
self.conv2 = nn.Sequential( # input shape (16, 14, 14)
nn.Conv2d(16, 32, 5, 1, 2), # output shape (32, 14, 14)
nn.ReLU(), # activation
nn.MaxPool2d(2), # output shape (32, 7, 7)
)
self.out = nn.Linear(32 * 7 * 7, 10) # fully connected layer, output 10 classes
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1) # flatten the output of conv2 to (batch_size, 32 * 7 * 7)
output = self.out(x)
return output, x # return x for visualization
注:本段代码来自莫烦Pytorch教程(感谢莫烦大神!)。
之所以只截取这一段,是因为它最重要,其它的处理数据集、输出图形等都是另外的学习范围。
后面的运行顺序:前向传播、计算损失、梯度清零、反向传播、更新神经网络参数(使用Pytorch框架)。
for step, (b_x, b_y) in enumerate(train_loader): # gives batch data, normalize x when iterate train_loader
output = cnn(b_x)[0] # 计算出结果(前向传播)
loss = loss_func(output, b_y) # 计算损失
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 更新神经网络参数
第一节 来看我的图,和代码一致!!!
这是你看过所有关于MNIST数据集(手写数字识别)
CNN卷积神经网路最棒的图!!!
————作者给萌新说

相信上面这两张图,很多小伙伴都很蒙13,而且众多视频也拿来讲,但是问题是,这两张图都跟MNIST数据集要做的训练不一样!跟写的代码也不一样,解释起来非常费劲,学习的小伙伴理解起来也非常费劲!第一张图是32×32的输入,第二张图是224×224的输入,所以我专门画了一张,这也许是你见过最靠谱的图,后面代码也通过它来讲:
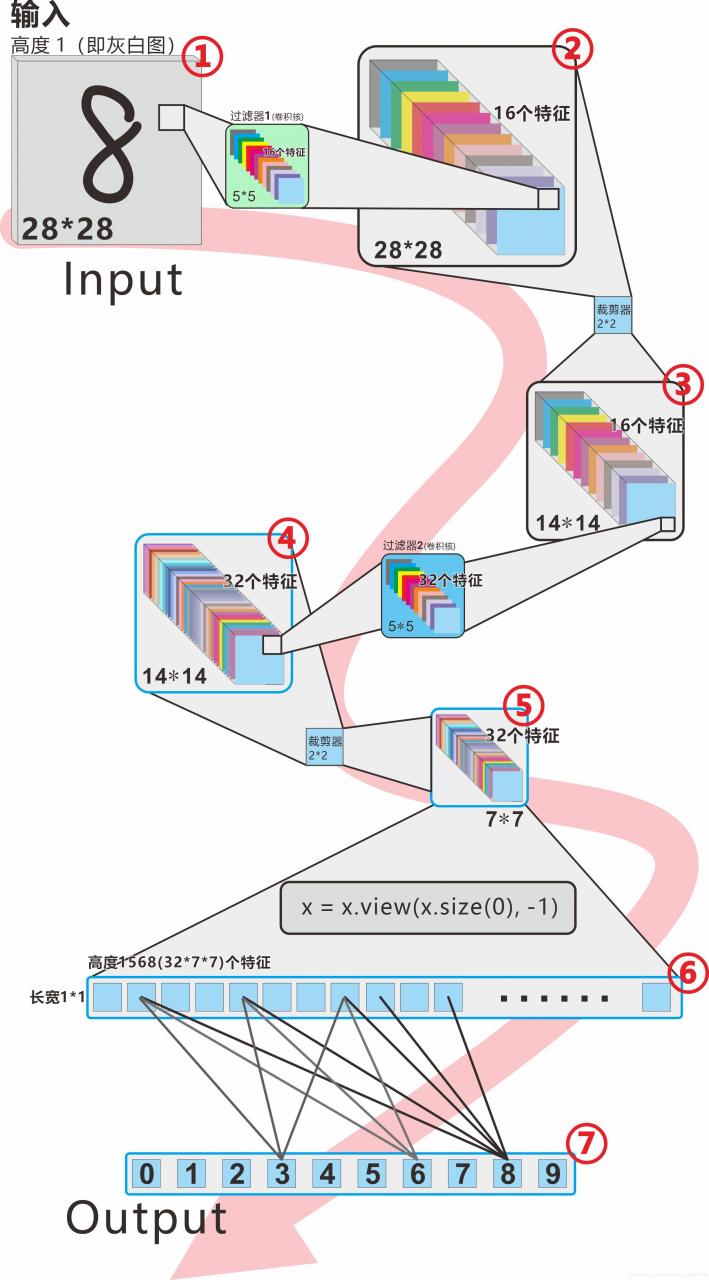
说明:
1、图中①至⑦是代表7个计算后的结果,后面对对应代码来讲。
2、注意图中的细节,比如颜色不同,边框不同,输入输出的对应画的位置不同,都是有含义的,并非随意画!
总述:首先一张28×28×1的手写图(来自MNIST数据集,Pytorch自带),经过一个过滤器(也叫卷积核),计算出28×28×16的特征图组,然后经过一个裁剪器,缩小成为14×14×16的特征图组,然后再经过一个过滤器(注意这个过滤器和第一个不一样!),变成14×14×32的特征图组,然后再经过一个裁剪器,变成7×7×32的特征图组,然后再压扁(没有减少压缩)变成1×1×1568的特征图,最后接上一个分类器0-9,即可。
注意上面说的特征图和特征图组,其实不是图片,是数字矩阵,即手写图片对应的数字矩阵。
第二节 别急,分阶段来聊咋一看很牛逼,可是还很多不懂。没事,我们一段一段来!
————作者给萌新说
第一小段 28×28×1灰度图 计算出 28×28×16 的特征图组(过滤器是5×5×32)(最难):
首先,输入一个28*28图片,对应到数据矩阵应该是:
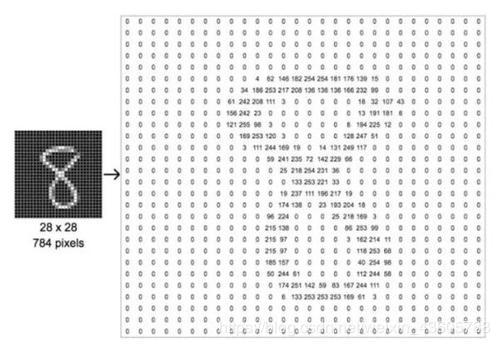
这是基础计算机知识,不用太多解释,即图片的每个像素点,都对应0-255的数字,在程序中,它就会变成这样的数据,这里其实就是数学矩阵。我们这里使用灰白图,所以它的高度只有1(如果是RGB就是高度为3)。
本文中提到的“图” ,在程序中 都是上图这种矩阵!
本文中提到的“图” ,在程序中 都是上图这种矩阵!
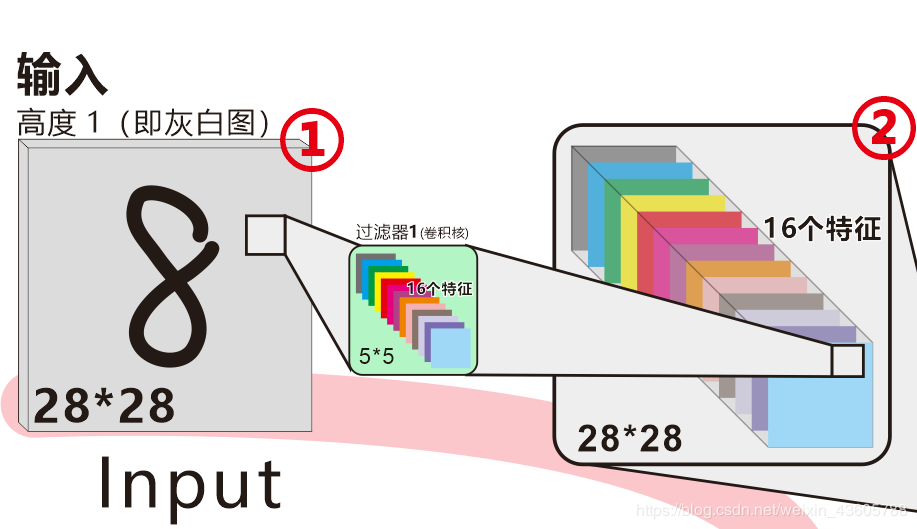
然后,它会被一个过滤器(也叫卷积核convolution kernel),这个过滤器的大小是5×5×16。
这时候很多小伙伴就要问,为啥是16高度(16张图)?这个16就是16个特征,即“记住这美女的鼻子眼睛嘴巴眉毛耳朵。。。的样子”,也许第1个特征是眼睛,第2个特征是嘴巴。。。。。
当然,你也可以理解为16张图,事实上也是(很多教程把这些特征单独罗列出结果给你看,但大多数并非手写数字,不参考)。
在我们这个例子里面,对应的就是,例如:第一个特征是,8这个数字上面一个圈下面一个圈。第二个特征8这个数字有一个手写留下的开口。第三个特征是。。。。(仅仅是举例)
当然,这些都是程序最后判断 “给的这图片是不是8 ?” 的重要标准。
然后,进行一次卷积计算Convolutions,得到一个特征图组(feature maps),这个特征图组就是② 。
对应代码:
nn.Conv2d(
in_channels=1, # 输入特征数是1(即28*28*1的灰度图片)
out_channels=16, # 输出特征数是16
kernel_size=5, # 过滤器的长和宽都是5
stride=1, # 步长是1,即一次移动1个像素,然后再计算(不明白看补充说明一)
padding=2, # 图片的上下左右各补充2个像素,这样输出的图片也是28*28(不明白看补充说明二)
),
这时候很多小伙伴又要问了,这16个特征,是谁决定的呢?
“16个特征”,这个数量是人来定的,是我在代码的时候输入的!但是,这“16个特征”都是些啥内容?并不是人来决定的,也不是手动输入的,而是通过整个神经网络反向传播自动调整的(就像人在生活中懂得分辨一个人,需要看他的五官一样),对应的Pytorch代码是:
loss.backward()
如果你对这个反向传播and计算梯度不了解,请看第一二集内容。
注意,这一小段只是讲的通俗好理解,事实上并不一定是上面说的“上面一个圈下面一个圈”这类特征,而是由计算机自己通过大量的学习数据(对应这里的是MNIST手写图片数据集),还不理解请看本文 第三节:我知道你想问什么。
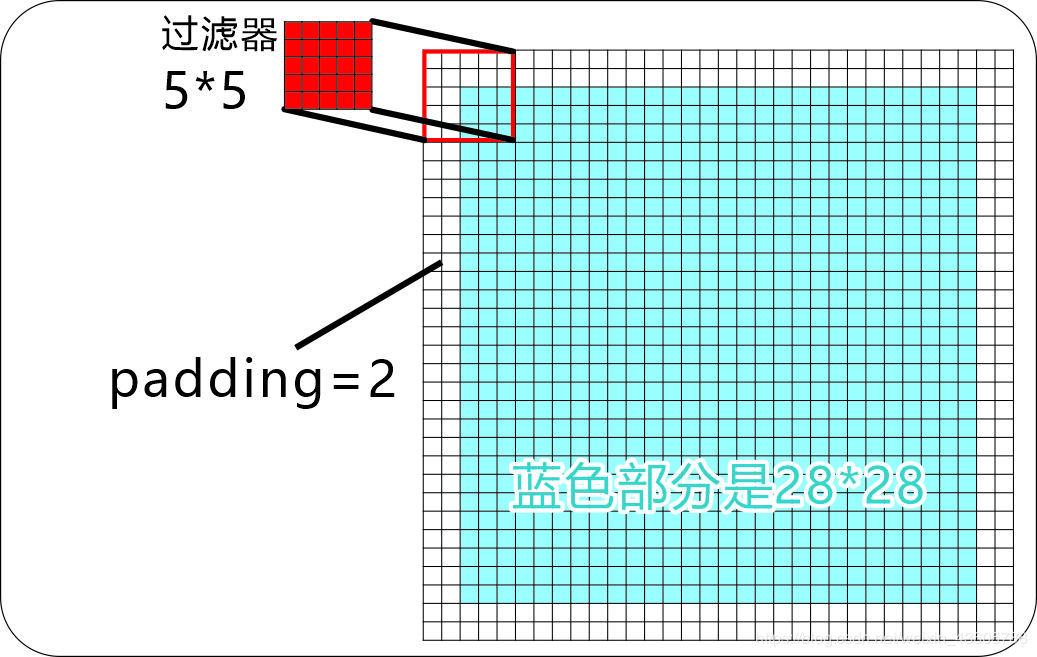
补充说明一stride=1 ,步长为一,就是说一次移动一个像素,一般从左到右开始,这里仅截取一部分移动过程展示:

padding=2 ,因为只有边缘补充2,最后计算出来的特征图组才和原来一样,注意下面红框的起始位置位置。边缘补充的这2个像素,通常是用0来填充(即值是0)。
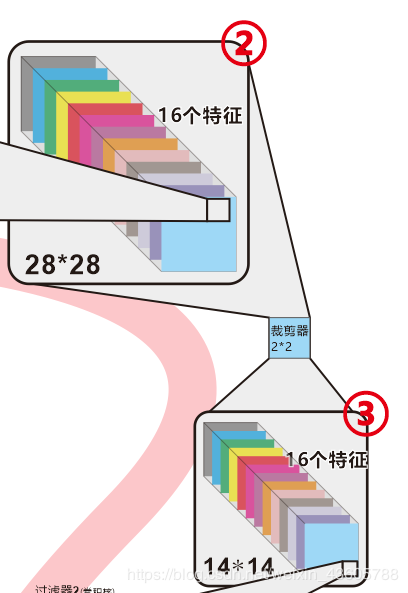
理解了上面讲的第一小段后,接下来的就容易了。仅仅是把上面这个28×28×16裁剪掉3/4,即剩下1/4,即14×14×16而已,对应代码:
nn.MaxPool2d(kernel_size=2)
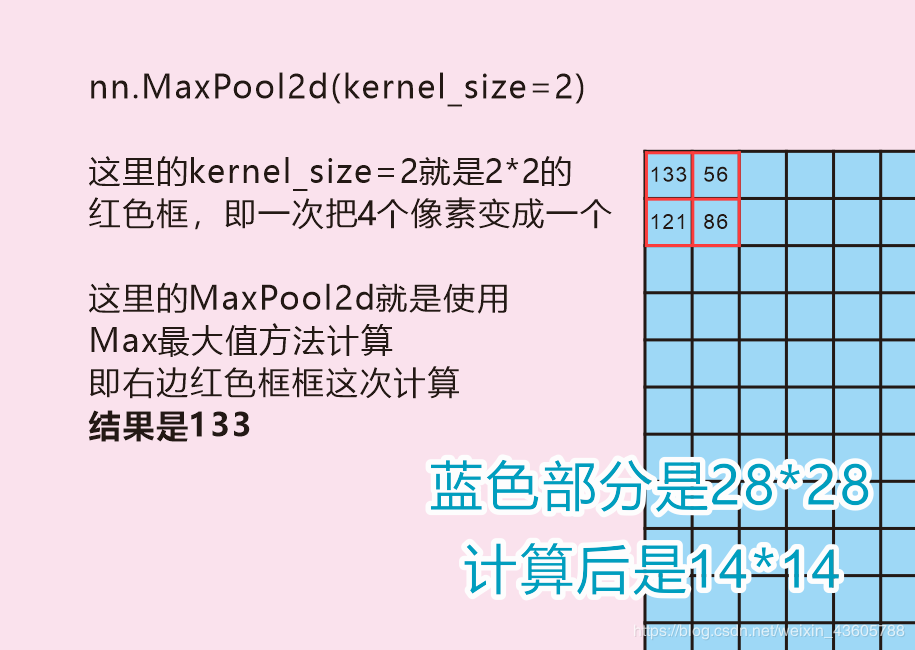
这里值得一说的就是:
1、裁剪后,16个特征保持不变。
2、长宽由原来的28×28变成14×14,其实就是缩小到原来的四分之一。
3、图中这个裁剪器其实也就是算法,没有高度。
有的小伙伴又要问了,这样的话,不就损失一些信息吗?事实证明(外国科学家表示)这没关系,不要在意这些细节。那为啥又要裁剪呢?是因为:电脑的计算量有限,太多的数据会严重拖慢计算时间。
第三小段 14×14×16的特征图组 再一次进行卷积(过滤器是5×5×32)计算,获得14×14×32的特征图组
这里,和上面的第二小节方法是一样的,但是不同的是,过滤器的是新的,并且是5×5×32 。
这里要注意这个是32个特征,所以输出后,也是32个特征,即14×14×32 。
对应代码:
nn.Conv2d(16, 32, 5, 1, 2)
第四小段 14×14×32的特征图进行裁剪,获得7×7×32的特征图
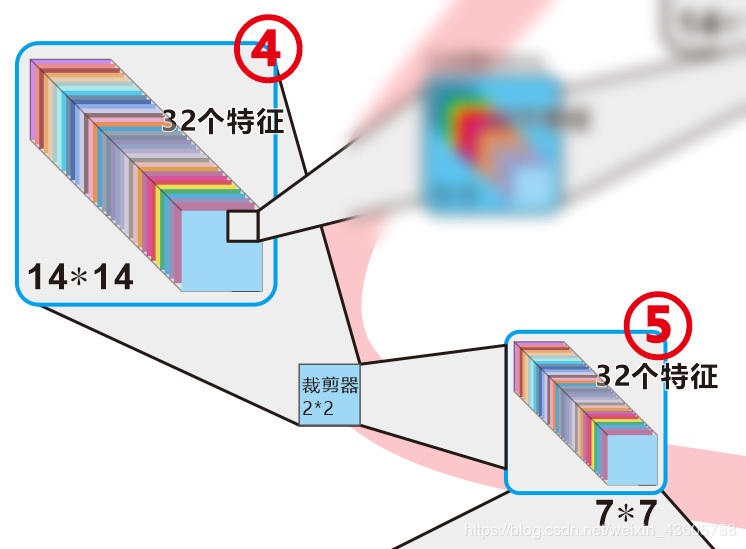
如果前面的都理解了,这里就没什么好说的。就是简单的裁剪,用的是取最大值的方法,对应代码是:
nn.MaxPool2d(2)
第五小段 将32×7×7的特征图组拍扁,变成1×1×1568的特征图(没有压缩也没有增加特征)
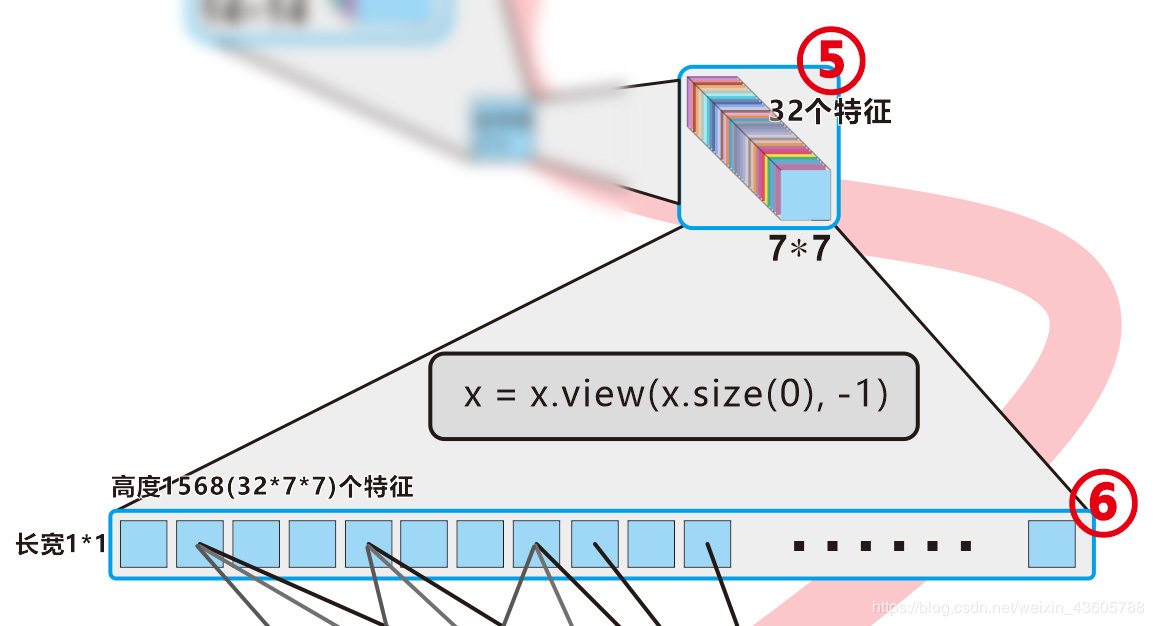
这里又有值得说的地方了。
这里的32×7×7个特征图组之后,要变成1×1×1568的特征图。对应代码:
x = x.view(x.size(0), -1)
但是这里,不要再用 特征图 这个词了!这里应该用 1568个神经网络节点组成的层 来说更易理解!没错!两者是一样的!!!
注意:本文说的所有的 “特征图” 都是 【神经网络节点组成的层】!
注意:本文说的所有的 “特征图” 都是 【神经网络节点组成的层】!
注意:本文说的所有的 “特征图” 都是 【神经网络节点组成的层】!
什么是层?看下面


你没有看错!确实是这样,难道你没发现代码中(上图红色框)这些都在建立神经网络吗?
也就是说,我们进行卷积过程也好,进行裁剪也好,都是搭建神经网络的方式在计算机中实现的,并且用的深度学习框架Pytorch。
上图中的红色框框内容就是本节每个小段都有的 “对应代码”。但是注意 nn.ReLU() 这个激活函数,我们不讲它,这个不了解的请看第一二集。
第六小段 完结撒花如果你已经看完上面的内容,并且也理解了,那么接下来就可以。。。可以再把本文从头看一遍!再仔细看一遍,不理解CNN的话。。。再看一遍!
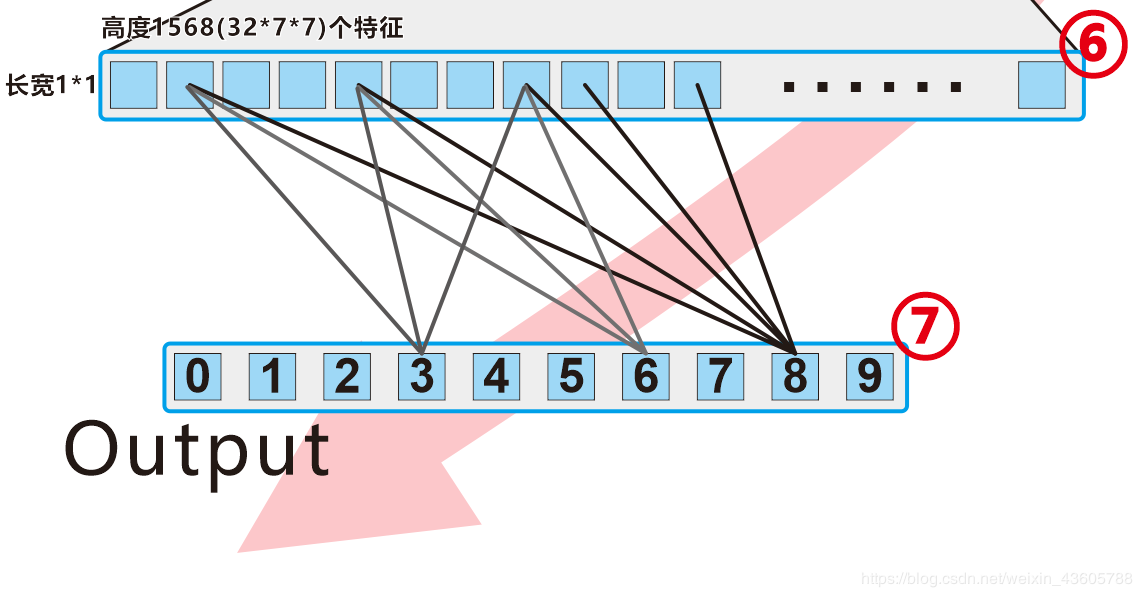
对应代码是:
self.out = nn.Linear(32 * 7 * 7, 10) #32*7*7就是1568个神经网络节点,这是输入层。10是输出层。
这里其实就是一个1568神经网络节点组成的层,链接到最后一个输出层(0-9个神经网络节点)而已。
而最多被激活的神经元节点指向8 !那么这个手写数字,程序就认为是 “8”,其它数字因为被激活的神经元比较少,代表可能性最低。
第七小段 把网络结构打印出来看看最后,我们把网络结构打印出来看看,

可以看出,依旧是按照我们写的代码罗列出来,值得关注的是:
0、sequential这个其实是表示,它里面的神经元层是 一层一层按顺序排列的。
1、kernel_siza = (5, 5) ,这里表示我们使用了5×5的卷积核长宽,而高度,则是前面那个 16
2、这里的stride就是步长,即采样的一步间隔多少像素,注意,这里是(1,1), 意思是从左往右是1步1个像素间隔,而从上往下,每一行向下移动一个像素。
3、padding = (2,2),这里说的是上下各补2行0作为空白补充,左右也各补充2列0 参考前面第二小段。
4、Conv2d() 这个函数就是“使用过滤器(卷积核)进行2维卷积计算”,其实还有Conv1d()跟Conv3d(),这里不细说。
5、MaxPool2d() 这个函数就是“进行2维池化”,其实也就是把之前的特征(即被卷积运算后的东西)进行2维池化,同样也有MaxPool1d()和MaxPool3d() 。
6、注意ReLU是激活函数,其实,它不应该被称为是一个神经网络层,他其实是跟在每个神经网络节点的东西。
7、最后的Linear就是线性的意思,与第一二集线性回归里面的Linear是一个意思,如果觉得有点乱,就直接理解成,“一长条”神经元的层,并且根据参数in_features = 1568 得知,一共有1568个神经元节点。
8、out_features = 10 ,就是输出10个神经元节点,也就是10个结果(数字0-9)。
第三节 我知道你想问什么还有一些疑问与说明:
0、特征、特征图、特征图组都是啥?特征,指的是统称。特征图,就是一张实实在在的图片,它代表某个地方的线条、轮廓之类,当然,在程序里面,它就是数字矩阵。特征图组,就是有若干个特征图组成的,也是一层神经网络“层” 。
1、经过两轮 【卷积计算(5×5×16或32的过滤器)+ 裁剪(2×2的裁剪器)】,为了是啥?卷积计算,是为了是进一步抽象出特征!
举例,
比如你看美女,你会看他的眼睛区域,嘴巴区域,但是眼睛和嘴巴并不足以让你记住 “啥是美女?” Why ?
那么你的脑子会更加进一步的抽象出 “其实你喜欢的是眼镜+红唇(女秘书款)” , 于是,下回你判断是不是美女,就会判断这个 “眼镜和红唇是否足够好(xing)看(gan)”!!
当然你喜欢的可能不止这样这款,还有很多其它类型。。。学术时间禁止开车。
这就是进一步抽象出特征!
裁剪,只是为了缩小数据量,没啥,别介意。
2、这里为啥数字8会连着比较多的线,而6和3也会连着线?因为计算机根据特征提取,计算机认为:不止输入的这个“8”像8,那个3也像啊!那个6也像啊!
为啥计算机会这么认为?因为经过特征提取后,计算机判断的标准,其实是各个笔画小段(特征)拼凑起来,看看哪个数字更像!?而3和6都有一定的相似度(比较低而已)。
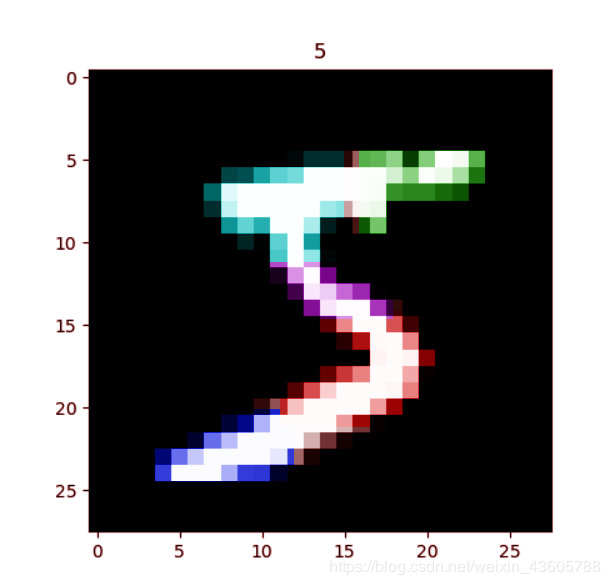
例如:
上面这个手写数字5的图片(28×28×1),它会被我们的神经网络模型中众多特征识别出上面这几个特征(不同颜色代表不同特征)。但不是说一个特征对应一个神经元节点,而是对应一个特征图的其中一张(如果这句不理解可以先不管)。而这几个特征是被大量的数据训练(提取)出来,而且是连向数字5,当然,也有一部分连向6(因为6也有一部分特征,比如红色的“拐弯”特征)。
(注:不同颜色代表不同特征而区分开,颜色本身没什么意义)
3、这么多特征,到底是谁来决定??第一次卷积计算,得到16个特征图组,第二次卷积计算,得到32个特征图组,这里的16和32,是人来定的,是我在程序里面写的参数。当然,你可以第一次写32,第二次写64,但是那样的话,运算起来就非常慢,这个需要综合考虑。
但是!注意!这16个和32个特征到底是啥?这就不由得我来确定了,而是程序经过大量的数据集来训练得出。
为啥大量的训练就可以得出这些特征呢?请参考上面第2点。
很多小伙伴应该最不能理解的就是这个了!这里细细说来

从头看这张图,为了不混淆观看文章的位置,这里加了点5毛特效。
首先我们来看特征图组,英文feature maps。
这个很显然,图中,③和⑤被裁剪器处理过的最终特征图,数量是16+32=48 。也就是说,这48个是真的可以变成图片的图!是可以打印出来看的!
可以理解这是在神经网络中真正起作用的地方!换句话说,整个Pytorch框架,就算其他网络节点不搭建起来,这48个特征图搭建起来,是完全一样的效果(虽然不太严谨,但是可以大致这么理解)。
然后我们来看神经元,③的神经元节点是多少呢?
是14×14×16=3136个!依次类推,⑤的神经元节点是7×7×32=1568个!
也就是说,**最终,这3136+1568=4704个神经元节点才是整个神经网络的核心!**他们起着决定性作用。
那其他的神经元节点呢?当然有用!只是那些不是负责辅助运算,就是负责裁剪。
(这样的描述应该最容易理解了。)
最后,回复这个问题“特征和神经元节点是啥关系?” 他们的关系就是,一个特征对应该图像素点个神经元节点!(7×7对应49个神经元节点)。
第四节 完整代码(来自莫烦Pytorch)亲测成功!"""
View more, visit my tutorial page: https://morvanzhou.github.io/tutorials/
My Youtube Channel: https://www.youtube.com/user/MorvanZhou
Dependencies:
torch: 0.4
torchvision
matplotlib
"""
# library
# standard library
import os
# third-party library
import torch
import torch.nn as nn
import torch.utils.data as Data
import torchvision
import matplotlib.pyplot as plt
# torch.manual_seed(1) # reproducible
# Hyper Parameters
EPOCH = 1 # train the training data n times, to save time, we just train 1 epoch
BATCH_SIZE = 50
LR = 0.001 # learning rate
DOWNLOAD_MNIST = False
# Mnist digits dataset
if not(os.path.exists('./mnist/')) or not os.listdir('./mnist/'):
# not mnist dir or mnist is empyt dir
DOWNLOAD_MNIST = True
train_data = torchvision.datasets.MNIST(
root='./mnist/',
train=True, # this is training data
transform=torchvision.transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to
# torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]
download=DOWNLOAD_MNIST,
)
# plot one example
print(train_data.train_data.size()) # (60000, 28, 28)
print(train_data.train_labels.size()) # (60000)
plt.imshow(train_data.train_data[0].numpy(), cmap='gray')
plt.title('%i' % train_data.train_labels[0])
plt.show()
# Data Loader for easy mini-batch return in training, the image batch shape will be (50, 1, 28, 28)
train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# pick 2000 samples to speed up testing
test_data = torchvision.datasets.MNIST(root='./mnist/', train=False)
test_x = torch.unsqueeze(test_data.test_data, dim=1).type(torch.FloatTensor)[:2000]/255. # shape from (2000, 28, 28) to (2000, 1, 28, 28), value in range(0,1)
test_y = test_data.test_labels[:2000]
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential( # input shape (1, 28, 28)
nn.Conv2d(
in_channels=1, # input height
out_channels=16, # n_filters
kernel_size=5, # filter size
stride=1, # filter movement/step
padding=2, # if want same width and length of this image after Conv2d, padding=(kernel_size-1)/2 if stride=1
), # output shape (16, 28, 28)
nn.ReLU(), # activation
nn.MaxPool2d(kernel_size=2), # choose max value in 2x2 area, output shape (16, 14, 14)
)
self.conv2 = nn.Sequential( # input shape (16, 14, 14)
nn.Conv2d(16, 32, 5, 1, 2), # output shape (32, 14, 14)
nn.ReLU(), # activation
nn.MaxPool2d(2), # output shape (32, 7, 7)
)
self.out = nn.Linear(32 * 7 * 7, 10) # fully connected layer, output 10 classes
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1) # flatten the output of conv2 to (batch_size, 32 * 7 * 7)
output = self.out(x)
return output, x # return x for visualization
cnn = CNN()
print(cnn) # net architecture
optimizer = torch.optim.Adam(cnn.parameters(), lr=LR) # optimize all cnn parameters
loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted
# following function (plot_with_labels) is for visualization, can be ignored if not interested
from matplotlib import cm
try: from sklearn.manifold import TSNE; HAS_SK = True
except: HAS_SK = False; print('Please install sklearn for layer visualization')
def plot_with_labels(lowDWeights, labels):
plt.cla()
X, Y = lowDWeights[:, 0], lowDWeights[:, 1]
for x, y, s in zip(X, Y, labels):
c = cm.rainbow(int(255 * s / 9)); plt.text(x, y, s, backgroundcolor=c, fontsize=9)
plt.xlim(X.min(), X.max()); plt.ylim(Y.min(), Y.max()); plt.title('Visualize last layer'); plt.show(); plt.pause(0.01)
plt.ion()
# training and testing
for epoch in range(EPOCH):
for step, (b_x, b_y) in enumerate(train_loader): # gives batch data, normalize x when iterate train_loader
output = cnn(b_x)[0] # cnn output
loss = loss_func(output, b_y) # cross entropy loss
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
if step % 50 == 0:
test_output, last_layer = cnn(test_x)
pred_y = torch.max(test_output, 1)[1].data.numpy()
accuracy = float((pred_y == test_y.data.numpy()).astype(int).sum()) / float(test_y.size(0))
print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.numpy(), '| test accuracy: %.2f' % accuracy)
if HAS_SK:
# Visualization of trained flatten layer (T-SNE)
tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000)
plot_only = 500
low_dim_embs = tsne.fit_transform(last_layer.data.numpy()[:plot_only, :])
labels = test_y.numpy()[:plot_only]
plot_with_labels(low_dim_embs, labels)
plt.ioff()
# print 10 predictions from test data
test_output, _ = cnn(test_x[:10])
pred_y = torch.max(test_output, 1)[1].data.numpy()
print(pred_y, 'prediction number')
print(test_y[:10].numpy(), 'real number')
注意一下几点:
1、要安装包有:Pytorch、Matplotlib、Sklearn
其中,Pytorch可能比较难安装,因为国内镜像好像已经挂了。装不上的小伙伴可参考下列文章:
离线安装Pytorch方法,亲测成功!!!
2、DOWNLOAD_MNIST = False 这个代码是要已经下载之后才使用。如果还没下载MNIST数据集,就要设置为True,然后自动下载。
3、莫烦Pytorch的代码Github地址:
https://github.com/MorvanZhou/PyTorch-Tutorial
注意: 如果下载这个,对应CNN代码文件名是“401_CNN.py” ,但是注意这个文件所在的文件夹目录结构应该这样才行(否则代码总会报错) :
CNN卷积神经网络,被视为人工智能的里程碑,自从被发表后,机器学习进入了大发展!这种“神奇”并不是不可以理解的,它的形成源于仿真生物的神经网络,这点上来说,非常成功。
其实说白了就是用卷积计算来提取特征,用裁剪来减少计算量,然后借用反向传播和计算梯度(梯度下降法),来更新各个神经元节点的参数,从而使得模型更准确(基于大量的训练数据)。
后续还有很多基于CNN进一步扩展与优化的各类“卷积”思维的神经网络,比如RNN,GAN,FCN等,这些都擅长于各种领域。但无论如何,如果没有理解好基础的CNN,是很难更进一步学习的。所以,这篇文章花费较多的精力,尽量从头解释CNN,并重新画图,这些都不容易,希望转载的兄弟把网址也转载,万分感谢!
(最后也感谢B站晓唦、迪哥、莫烦、覃秉丰、同济子豪兄以及公开视频作者,业界大神李宏毅、吴恩达等等)

作者:weixin_43605788