人工智能学习Pytorch进阶操作教程
一、合并与分割
1.cat拼接
2.stack堆叠
3.拆分
①Split按长度拆分
②Chunk按数量拆分
二、基本运算
1.加减乘除
2.矩阵相乘
3.次方计算
4. clamp
三、属性统计
1.求范数
2.求极值、求和、累乘
3. dim和keepdim
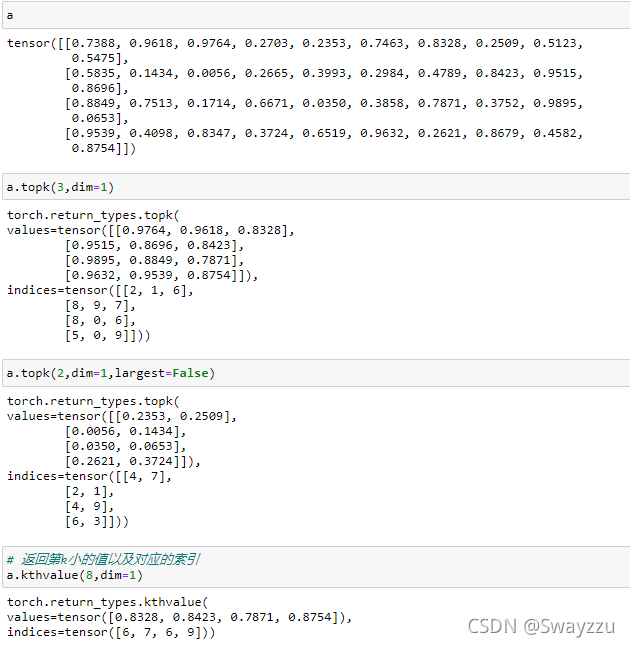
4.topk和kthvalue
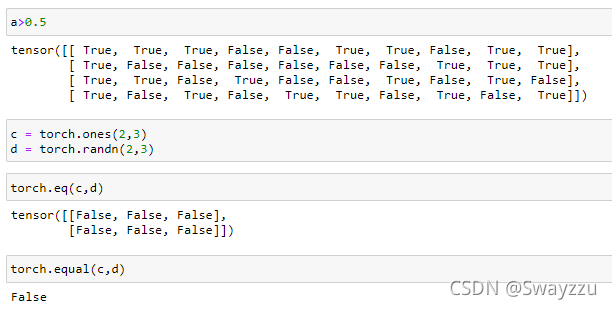
5.比较运算
6.高阶操作
①where
②gather
一、合并与分割 1.cat拼接直接按照指定的dim维度进行合并,要求除了所需要合并的维度之外,其他的维度需要是一样的
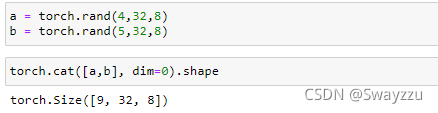
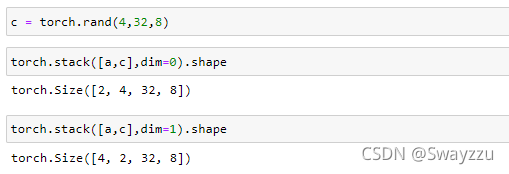
例:此处创建一个和a一样的tensor,按照某一维度进行stack,就会在堆叠的维度前面,生成一个新的维度,用以进行选择,比如新生成了一个2维,就可以通过0,1进行选择。具体是什么意义,取决于实际的问题。
比如两个班成绩单用stack合并,生成的新维度,就可以选择0或1来选择这个新维度,从而达到选择班级的目的。
第一个参数可以是单独的数字a,意思是每一个拆分出来的部分有a个数据;可以是一个类似list的对象b,意思是把数据按照b里面的方式拆分,拆分成len(b)个tensor。

传入的第一个参数就是拆成几个chunk,然后把原来的维度除以这个数量即可。
比如下面的例子,原来维度是[2,32,8],chunk参数传入2,就需要拆成2个,则2/2=1,最终每一个的维度变为[1,32,8]。

和numpy中的一致。也可以使用torch.add等方法。

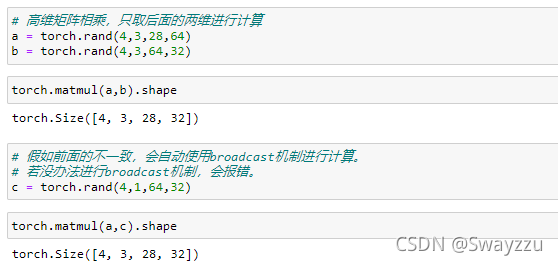
注意,*就是元素与元素相乘,而矩阵相乘可以用以下两种:torch.matmul,@

如果是高维矩阵相乘,计算的其实就是最后的两个维度的矩阵乘法。
和numpy中一致,可以使用**来计算任意次方。此外.pow()也可以计算。

指数和对数计算也基本一致,log默认是以e为底的。

通常用于当出现梯度过大等情况时,对梯度进行裁剪。通过输入最大最小值,目标中超出最大值的按最大值来;低于最小值的按最小值来。

注意一点:求哪个维度的范数,哪个维度就会被消掉。

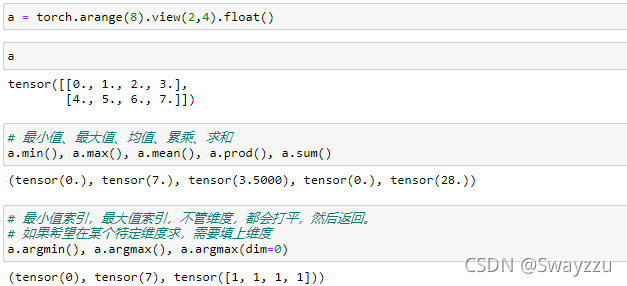
在很多方法中,都可以对dim进行设置。如果不设置,就是把所有数据展开后,求全局的。
注意这里的dim,a的形状是[4,10],求最大值时,如果设置dim=1,也就是列,个人理解,意思是结果的维度需要是列,那么就是把整行的数值进行计算找最大值,最后返回一个列作为结果。

topk参数:k(前k个最大值),dim(以dim的维度返回结果)
这个方法默认的是返回的最大值,同时会返回它们的索引。
kthvalue参数:k(第k小的值),dim
和Numpy中的一致。如果使用torch.eq方法,返回每个对应位置的结果;如果使用torch.equal方法,返回的是整体对比的结果。

索引行数小于等于表的行数。也就是说,既然要用索引来去找表中的内容,就不能超过表的索引长度。索引在传入gather方法中的时候,必须要转换成Long的类型。
举例如下:
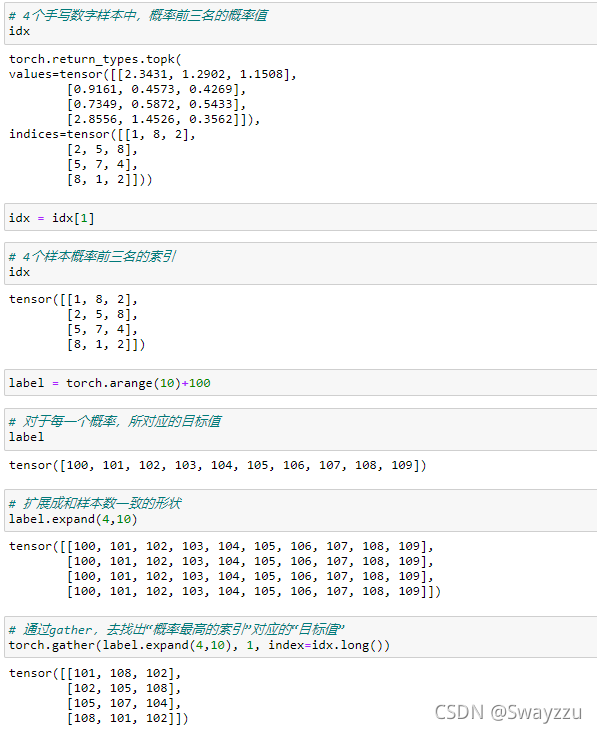
返回值的形状一定是索引的形状,因为就是按照索引去取的值。返回值的内容就来自于输入的input,根据索引获得的对应的值。
以上就是人工智能学习Pytorch进阶操作教程的详细内容,更多关于PyTorch进阶的资料请关注软件开发网其它相关文章!