【人工智能学习】【十一】循环神经网络进阶
RNN(Recurrent Neural Network,循环神经网络)主要应用在自然语言处理、机器翻译、情感分析、时序序列问题。这些的功能的共同特点是具有时序性。卷积神经网络是没有记忆性的(我对这句话的理解是神经元之间没有信息传递,各个WWW矩阵是独立计算的,当然不是说整个网络没有记忆,只是记忆是独立的),RNN通过神经元之间的信息传递保留了记忆(就是一个state变量,加变量是为了增加模型的非线性表达能力),但在长序列,即长时间步的问题上,梯度消失会让网络变得不可训练。

Ht=f(XtWxh+Hh−1Whh+bh)H_t=f(X_tW_{xh}+H_{h-1}W_{hh}+b_h)Ht=f(XtWxh+Hh−1Whh+bh)
在【人工智能学习】【六】循环神经网络中介绍了RNN的结构,RNN需要按照时间序列进行展开可能导致梯度消失和梯度爆炸的问题【人工智能学习】【八】梯度消失与梯度爆炸,梯度爆炸我们可以dropout,做正则化来解决。
长短期记忆网络(LSTM,Long Short-Term Memory)(1997年)和后来出现的GRU模型(2014年),都解决了梯度消失和语义前后顺序的问题。这两者差不多,但是为啥又出现了了GRU,论文里说是它比LSTM好算。
长短期记忆网络(LSTM,Long Short-Term Memory),RNN的变种。
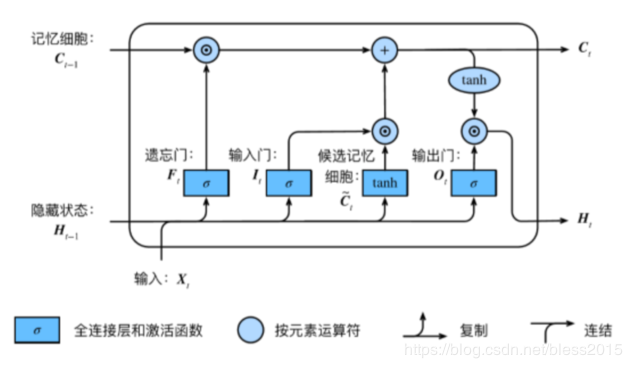
上图对比RNN,似乎结构上差不多,但是里面多了很多东西。但是模型虽然复杂了,不要忘了诞生于1997年的LSTM是解决了RNN的问题:梯度消失和长序列记忆(说白了就是和前面离得太远了,梯度传过来已经接近于0了)。所以这些结构看上去应该是和梯度消失问题有关。
RNN的神经元节点上有两个输入:1、ttt时刻的输入XtX_tXt;2、t−1t-1t−1时刻的隐含层节点传过来的状态Ht−1H_{t-1}Ht−1。
现在得出一个很直观的结论:既然当前节点无法记忆到很长时间序列之前的信息,那么我再开辟一条通道,用来传递之前的信息。即在RNN上加上一条传送带(adding a carry track),这条传送带上有之前神经元节点的记忆信息Ct−1C_{t-1}Ct−1(C是carry track里的C),这里的Ct−1C_{t-1}Ct−1尽管也是一个状态,好像和之前神经元节点的Ht−1H_{t-1}Ht−1(state)没什么区别。但是RNN中的Ht−1H_{t-1}Ht−1是每次都会进行下面的计算来更新,并传递到下一个神经元节点。
Ht=f(XtWxh+Hh−1Whh+bh)H_t=f(X_tW_{xh}+H_{h-1}W_{hh}+b_h)Ht=f(XtWxh+Hh−1Whh+bh)
这里的这个Ct−1C_{t-1}Ct−1就不是这么计算的了,极端情况试想一下,Ct−1C_{t-1}Ct−1永远只参与Ht−1H_{t-1}Ht−1的计算,但是自己永远不被计算,初始的C0C_{0}C0值会沿着这条carry track,从第一个节点传到最后一个节点,途中值是复制一份自己来计算Ht−1H_{t-1}Ht−1的值。
CCC既然是传送各个神经元的状态,那么CtC_tCt应该是要和下面这3个变量有关系:Ct−1C_{t-1}Ct−1、XtX_{t}Xt、Ht−1H_{t-1}Ht−1。Ct−1C_{t-1}Ct−1负责将上一层的信息传过来,XtX_{t}Xt负责计算本时刻节点的状态,是否和上一层的Ht−1H_{t-1}Ht−1有关。
所以,现在HtH_{t}Ht的计算和3个变量有关了:Ht−1H_{t-1}Ht−1、Ct−1C_{t-1}Ct−1、XtX_{t}Xt,加入到公式中
Ht=f(XtWxh+Hh−1Whh+Ct−1W+bh)H_t=f(X_tW_{xh}+H_{h-1}W_{hh}+C_{t-1}W+b_h)Ht=f(XtWxh+Hh−1Whh+Ct−1W+bh)
这里先用Ct−1WC_{t-1}WCt−1W暂时表示用Ct−1C_{t-1}Ct−1对模型起到的作用。
如果神经元节点自己会思考,他会做什么事?
1、传过来的状态CCC我不仅自己用,我还会加上自己的状态把他继续往后传。(传话人设,这是基本人设)
2、传过来的状态CCC我不想用,那么我有遗忘的权利,我只想把我这个节点产生的状态CCC传递到未来。(称作霸道人设,这是霸道加持)
传话人设对应的是输入门,反映到数学上是WinputW_{input}Winput,缩写成WiW_{i}Wi,这个输入门指的是输入到CtC_tCt中的状态,控制有多少XtX_tXt的信息要被保存到状态CtC_tCt上。
霸道人设对应的是遗忘门,反映到数学上是WforgetW_{forget}Wforget,缩写成WfW_{f}Wf,控制有多少Ct−1C_{t-1}Ct−1要被丢弃。
考虑输入门是和XtX_tXt、Ht−1H_{t-1}Ht−1有关,那么
It=XtXxi+Ht−1Whi+biI_t=X_tX_{xi}+H_{t-1}W_{hi}+b_iIt=XtXxi+Ht−1Whi+bi
这个公式就是之前RNN的公式,这里的输入门还没有用到Ct−1C_{t-1}Ct−1呢
考虑遗忘门是和XtX_tXt、Ht−1H_{t-1}Ht−1、Ct−1C_{t-1}Ct−1有关。那么
Ft=XtWxf+Ht−1Whf+bfF_t=X_tW_{xf}+H_{t-1}W_{hf}+b_fFt=XtWxf+Ht−1Whf+bf
原来RNN的输出这里叫输出门,和XtX_tXt、Ht−1H_{t-1}Ht−1有关
Ot=XtWxo+Ht−1Who+boO_t=X_tW_{xo}+H_{t-1}W_{ho}+b_oOt=XtWxo+Ht−1Who+bo
遗忘门、输入门、输出门上都有sigmod函数,将值映射到[0,1][0,1][0,1]之间,等于0意味着全部丢弃,等于1意味着全部保留,这个结果就是通过门的信息量大小。所以上面三个式子的最终形态如下:
It=sigmod(XtXxi+Ht−1Whi+bi)I_t=sigmod(X_tX_{xi}+H_{t-1}W_{hi}+b_i)It=sigmod(XtXxi+Ht−1Whi+bi)
Ft=sigmod(XtWxf+Ht−1Whf+bf)F_t=sigmod(X_tW_{xf}+H_{t-1}W_{hf}+b_f)Ft=sigmod(XtWxf+Ht−1Whf+bf)
Ot=sigmod(XtWxo+Ht−1Who+bo)O_t=sigmod(X_tW_{xo}+H_{t-1}W_{ho}+b_o)Ot=sigmod(XtWxo+Ht−1Who+bo)
到这里还是没有完,还有一个候选记忆,它的计算是:
Ct~=tanh(XtWxc+Ht−1Whc+bc)\widetilde{C_t}=tanh(X_tW_{xc}+H_{t-1}W_{hc}+b_c)Ct=tanh(XtWxc+Ht−1Whc+bc)
最终的长期记忆状态CtC_tCt的计算公式:
Ct=Ft⋅Ct−1+It⋅Ct~C_t=F_t·C_{t-1}+I_t·\widetilde{C_t}Ct=Ft⋅Ct−1+It⋅Ct
候选记忆是将要记忆的XtX_tXt和Ht−1H_{t-1}Ht−1通过tanh激活函数放缩到[−1,1][-1,1][−1,1]之间,然后通过输入门训练的WiW_iWi来决定哪些记忆将会被记忆。如果不通过tanh将XtX_tXt和Ht−1H_{t-1}Ht−1的计算结果放缩到[−1,1][-1,1][−1,1]之间,状态CtC_tCt可能会爆炸了(没验证)。我觉得这样理解不是很好,但是这个东西感觉和输入门有点功能重复。
最后的输出计算公式:
Ht=Ot⋅tanh(Ct)H_t=O_t·tanh(C_t)Ht=Ot⋅tanh(Ct)
参数初始化
def get_params():
def _one(shape):
ts = torch.tensor(np.random.normal(0, 0.01, size=shape), device=device, dtype=torch.float32)
return torch.nn.Parameter(ts, requires_grad=True)
def _three():
return (_one((num_inputs, num_hiddens)),
_one((num_hiddens, num_hiddens)),
torch.nn.Parameter(torch.zeros(num_hiddens, device=device, dtype=torch.float32), requires_grad=True))
W_xi, W_hi, b_i = _three() # 输入门参数
W_xf, W_hf, b_f = _three() # 遗忘门参数
W_xo, W_ho, b_o = _three() # 输出门参数
W_xc, W_hc, b_c = _three() # 候选记忆细胞参数
# 输出层参数
W_hq = _one((num_hiddens, num_outputs))
b_q = torch.nn.Parameter(torch.zeros(num_outputs, device=device, dtype=torch.float32), requires_grad=True)
return nn.ParameterList([W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q])
def init_lstm_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device),
torch.zeros((batch_size, num_hiddens), device=device))
模型定义
def lstm(inputs, state, params):
[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q] = params
(H, C) = state
outputs = []
for X in inputs:
I = torch.sigmoid(torch.matmul(X, W_xi) + torch.matmul(H, W_hi) + b_i)
F = torch.sigmoid(torch.matmul(X, W_xf) + torch.matmul(H, W_hf) + b_f)
O = torch.sigmoid(torch.matmul(X, W_xo) + torch.matmul(H, W_ho) + b_o)
C_tilda = torch.tanh(torch.matmul(X, W_xc) + torch.matmul(H, W_hc) + b_c)
C = F * C + I * C_tilda
H = O * C.tanh()
Y = torch.matmul(H, W_hq) + b_q
outputs.append(Y)
return outputs, (H, C)
模型训练
num_epochs, num_steps, batch_size, lr, clipping_theta = 160, 35, 32, 1e2, 1e-2
pred_period, pred_len, prefixes = 40, 50, ['分开', '不分开']
d2l.train_and_predict_rnn(lstm, get_params, init_lstm_state, num_hiddens,
vocab_size, device, corpus_indices, idx_to_char,
char_to_idx, False, num_epochs, num_steps, lr,
clipping_theta, batch_size, pred_period, pred_len,
prefixes)
torch简介实现
num_hiddens=256
num_epochs, num_steps, batch_size, lr, clipping_theta = 160, 35, 32, 1e2, 1e-2
pred_period, pred_len, prefixes = 40, 50, ['分开', '不分开']
lr = 1e-2 # 注意调整学习率
lstm_layer = nn.LSTM(input_size=vocab_size, hidden_size=num_hiddens)
model = d2l.RNNModel(lstm_layer, vocab_size)
d2l.train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes)
GRU
门控循环单元(GRU),RNN的变种,LSTM的变种。GRU 保持了 LSTM 的效果同时又使结构更加简单。GRU 只剩下两个门,即更新门和重置门。在LSTM中,我们是引出了一个carry track,也就是状态CCC,这个在LSTM是单独一条计算链。跟着GRU思考,**Ct−1C_{t-1}Ct−1和RNN中的Ht−1H_{t-1}Ht−1是不是可以合并呢?**GRU就是这样设计的。

重置门(reset gate):决定有多少信息被忽略。
更新门(update gate):决定有多少前一个神经元传来的信息被用到这个神经元的计算。
来看重置门和更新门的计算
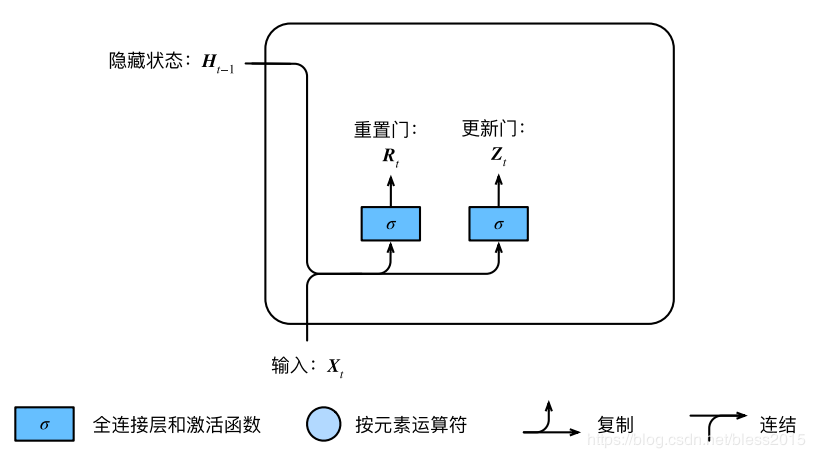
显然
Rt=sigmod(XtWxr+Ht−1Whr+br)R_t=sigmod(X_tW_{xr}+H_{t-1}W_{hr}+b_r)Rt=sigmod(XtWxr+Ht−1Whr+br)
Zt=sigmod(XtWxz+Ht−1Whz+bz)Z_t=sigmod(X_tW_{xz}+H_{t-1}W_{hz}+b_z)Zt=sigmod(XtWxz+Ht−1Whz+bz)
RtR_tRt 和更新ZtZ_tZt 的值域都为[0, 1],公式很简洁
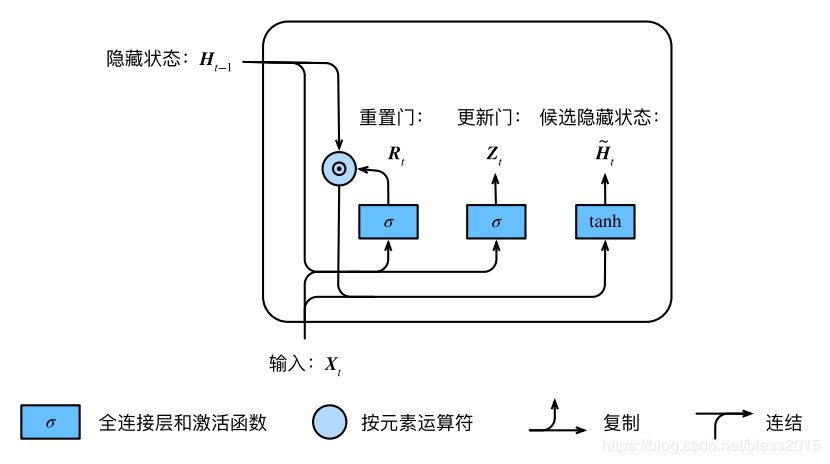
Ht~=tanh(XtWxh+(Rt⋅Ht−1)Whh+bh)\widetilde{H_t}=tanh(X_tW_{xh}+(R_t·H_{t-1})W_{hh}+b_h)Ht=tanh(XtWxh+(Rt⋅Ht−1)Whh+bh)
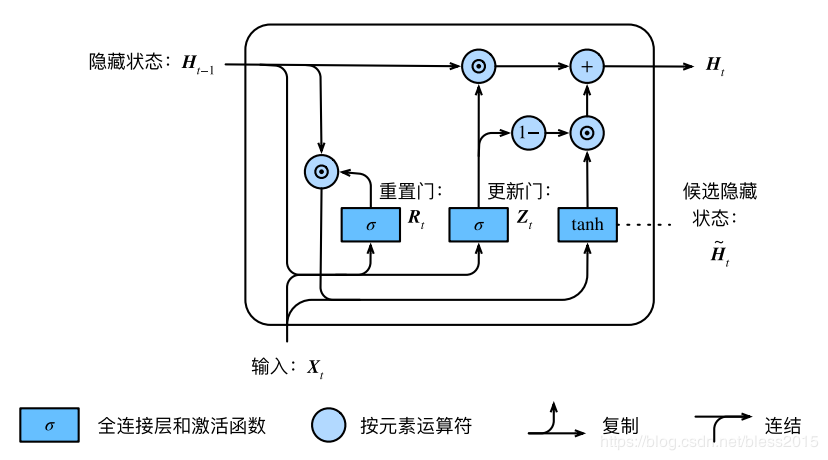
按照上图的计算方式,最后输出的HtH_tHt为:
Ht=Zt⋅Ht−1+(1−Zt)⋅Ht~H_t=Z_t·H_{t-1}+(1-Z_t)·\widetilde{H_t}Ht=Zt⋅Ht−1+(1−Zt)⋅Ht
载入数据集
import numpy as np
import torch
from torch import nn, optim
import torch.nn.functional as F
import os
import sys
import d2l_jay9460 as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
(corpus_indices, char_to_idx, idx_to_char, vocab_size) = d2l.load_data_jay_lyrics()
初始化
num_inputs, num_hiddens, num_outputs = vocab_size, 256, vocab_size
print('will use', device)
def get_params():
def _one(shape):
ts = torch.tensor(np.random.normal(0, 0.01, size=shape), device=device, dtype=torch.float32) #正态分布
return torch.nn.Parameter(ts, requires_grad=True)
def _three():
return (_one((num_inputs, num_hiddens)),
_one((num_hiddens, num_hiddens)),
torch.nn.Parameter(torch.zeros(num_hiddens, device=device, dtype=torch.float32), requires_grad=True))
W_xz, W_hz, b_z = _three() # 更新门参数
W_xr, W_hr, b_r = _three() # 重置门参数
W_xh, W_hh, b_h = _three() # 候选隐藏状态参数
# 输出层参数
W_hq = _one((num_hiddens, num_outputs))
b_q = torch.nn.Parameter(torch.zeros(num_outputs, device=device, dtype=torch.float32), requires_grad=True)
return nn.ParameterList([W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q])
def init_gru_state(batch_size, num_hiddens, device): #隐藏状态初始化
return (torch.zeros((batch_size, num_hiddens), device=device), )
模型定义
def gru(inputs, state, params):
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
Z = torch.sigmoid(torch.matmul(X, W_xz) + torch.matmul(H, W_hz) + b_z)
R = torch.sigmoid(torch.matmul(X, W_xr) + torch.matmul(H, W_hr) + b_r)
H_tilda = torch.tanh(torch.matmul(X, W_xh) + R * torch.matmul(H, W_hh) + b_h)
H = Z * H + (1 - Z) * H_tilda
Y = torch.matmul(H, W_hq) + b_q
outputs.append(Y)
return outputs, (H,)
模型训练
num_epochs, num_steps, batch_size, lr, clipping_theta = 160, 35, 32, 1e2, 1e-2
pred_period, pred_len, prefixes = 40, 50, ['分开', '不分开']
d2l.train_and_predict_rnn(gru, get_params, init_gru_state, num_hiddens,
vocab_size, device, corpus_indices, idx_to_char,
char_to_idx, False, num_epochs, num_steps, lr,
clipping_theta, batch_size, pred_period, pred_len,
prefixes)
torch简洁实现
num_hiddens=256
num_epochs, num_steps, batch_size, lr, clipping_theta = 160, 35, 32, 1e2, 1e-2
pred_period, pred_len, prefixes = 40, 50, ['分开', '不分开']
lr = 1e-2 # 注意调整学习率
gru_layer = nn.GRU(input_size=vocab_size, hidden_size=num_hiddens)
model = d2l.RNNModel(gru_layer, vocab_size).to(device)
d2l.train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes)
深度循环神经网络
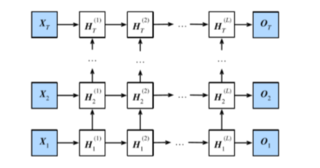
深度循环神经网络属于一种模型层次结构上的改进,考虑的是模型复杂度(模型的表现力)
Ht(1)=f(XtWxh(1)+Ht−1(1)Whh(1)+bh(1))H^{(1)}_t=f(X_tW_{xh}^{(1)}+H_{t-1}^{(1)}W_{hh}^{(1)}+b_h^{(1)})Ht(1)=f(XtWxh(1)+Ht−1(1)Whh(1)+bh(1))
Ht(l)=f(XtWxh(l)+Ht−1(l)Whh(l)+bh(l))H^{(l)}_t=f(X_tW_{xh}^{(l)}+H_{t-1}^{(l)}W_{hh}^{(l)}+b_h^{(l)})Ht(l)=f(XtWxh(l)+Ht−1(l)Whh(l)+bh(l))
深度循环神经网络的结构,RNN、LSTM、GRU,都可以扩展,就是把之前隐含层的输出(不是装填)当做输入,按序列输入到另一个RNN中、LSTM、GRU中,这个可以看做一层,多个层连接到一起就构成了深度循环神经网络。
所以这只是一个结构上的变化,代码实现
num_hiddens=256
num_epochs, num_steps, batch_size, lr, clipping_theta = 160, 35, 32, 1e2, 1e-2
pred_period, pred_len, prefixes = 40, 50, ['分开', '不分开']
lr = 1e-2 # 注意调整学习率
gru_layer = nn.LSTM(input_size=vocab_size, hidden_size=num_hiddens,num_layers=2)
model = d2l.RNNModel(gru_layer, vocab_size).to(device)
d2l.train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes)
num_layers=2意味着有2层。这里可以自己选择有多少层。不是层数越多越好,要根据模型。层数越多模型越复杂,对数据集要求就越多。要看实际情况。
双向循环神经网络(BRNN)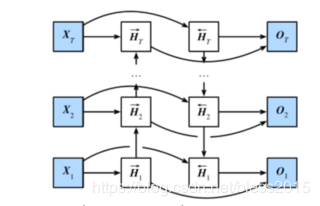
双向循环神经网络属于一种模型层次结构上的改进,BRNN考虑的是输入序列的反向序列对模型的影响。比如单靠前面一句话,没有办法得到准确结论的情况。
模型分两步计算:
1、正向计算,和普通RNN一样。
2、反向计算,逆向的计算和普通RNN一样。
Ht→=f(XtWxhf+Ht−1Whhf+bhf)\overrightarrow{H_t}=f(X_tW_{xh}^{f}+H_{t-1}W_{hh}^f+b_h^{f})Ht=f(XtWxhf+Ht−1Whhf+bhf)
Ht←=f(XtWxhb+Ht−1Whhb+bhb)\overleftarrow{H_t}=f(X_tW_{xh}^{b}+H_{t-1}W_{hh}^b+b_h^{b})Ht=f(XtWxhb+Ht−1Whhb+bhb)
向左的箭头是正向,向右的是反向。
现在得到两个H输出了。普通RNN的输出是下面这样:
Y=HtWhy+byY=H_tW_{hy}+b_yY=HtWhy+by
双向的有两个HHH,做一个数学上的拼接
Ht=(Ht→,Ht←)H_t=(\overrightarrow{H_t},\overleftarrow{H_t})Ht=(Ht,Ht)
然后
Y=HtWhy+byY=H_tW_{hy}+b_yY=HtWhy+by
torch封装的很好了,通过一个bidirectional=True开关来打开双向循环就好。
num_hiddens=128
num_epochs, num_steps, batch_size, lr, clipping_theta = 160, 35, 32, 1e-2, 1e-2
pred_period, pred_len, prefixes = 40, 50, ['分开', '不分开']
lr = 1e-2 # 注意调整学习率
gru_layer = nn.GRU(input_size=vocab_size, hidden_size=num_hiddens,bidirectional=True)
model = d2l.RNNModel(gru_layer, vocab_size).to(device)
d2l.train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes)
作者:番茄发烧了