论文阅读 -- 时序动作提名--CTAP: Complementary Temporal Action Proposal Generation
时序动作提名生成的方法大致可以分为三类,基于滑动窗口的(SCNN-prop ,TURN),基于动作性分数判定的(TAG,BSN),将前两者的融合(CTAP,BMN,DBG)。这篇文章是第三种方法的最早的几篇论文了。
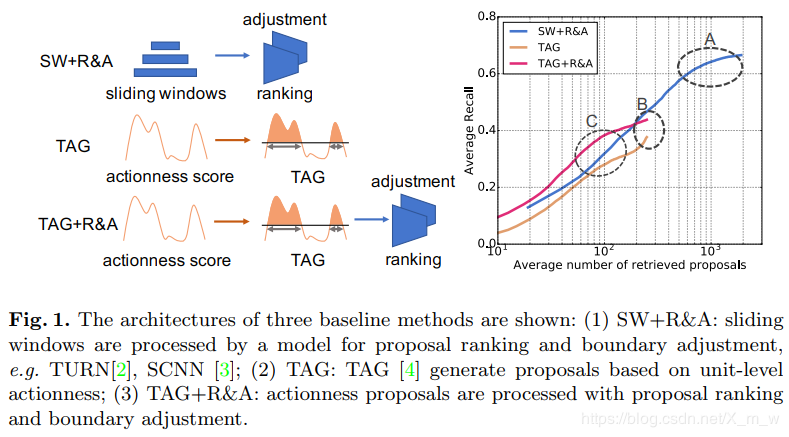
基于滑动窗口的方法,将视频按照不同尺度划分为一系列窗口,再对这些窗口判断是否包含动作实例,这种方法的缺点是,边界不够精确(虽然有一些方法可以调整边界),就会造成只有大量检索proposal才能达到高AR,如图1中的圆圈A所示。
基于动作性分数(actionness score),这种方法是对视频的每个位置进行分类评分(该位置在动作内的得分,或者直接二分类),再将高分数结合成proposal;该方法对分类器要求很高,如果分类出现差错救护导致忽略一些proposal,所以AR性能的上限被限制如图1的B。
融合的方法,基于动作性的proposals的边界更精确,因为它们在更精细的层次上被预测,而窗口级排名可能更有有识别力的,因为它用到更多的全局上下文信息当动作性分数的质量比较低时,actionness-based方法可能忽略一些正确的proposals;滑动窗口可以统一的覆盖视频中的所有段。 利用滑动窗口的部分来自适应的补足第二种方法的缺失,就是第三种融合的方法。
文章提出一个新的互补时序动作提名(CTAP)生成器包含三个模型:
初始proposal生成,输出actionness proposals和滑动窗口proposals。 proposal互补滤波器,首先判断actionness方法是否可能漏掉某些proposal,并从滑动窗口proposals中收集过来,组成新的proposals。 proposals排名与边界调整,设计了一个时序卷积神经网络,时序排序信息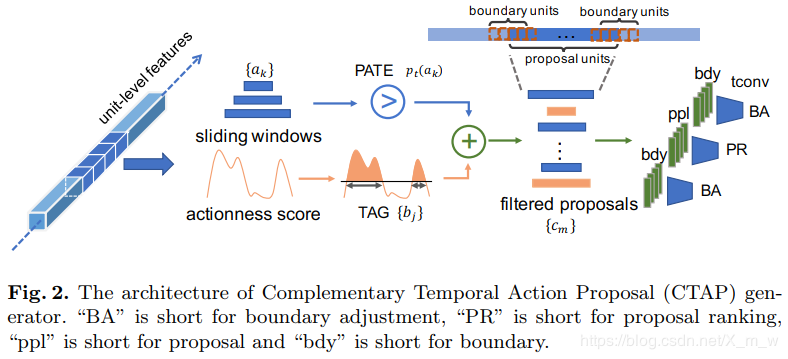 2.1 初始提名生成
2.1 初始提名生成
这一部分先介绍视频预处理,然后是actionness方法生成proposals和滑动窗口生成proposals。
视频预处理
根据之前的方法,一个未裁剪的长视频被分割成片段,每个片段包含nun_unu个连续的帧。再通过视觉编码器EvE_vEv提取片段级的表示xu=Eu(u)∈Rdf\mathbf x_u=E_u(u)\in\Bbb{R}^{d_f}xu=Eu(u)∈Rdf。在这个实验中采用two-stream CNN模型作为视觉编码器。
Actionness方法生成proposals
基于上面的片段特征,训练一个分类器为每一个片段生成actionness分数。这里是采用的两层时间卷积网络,每次输入tat_ata个连续的片段特征,x∈Rta×df\mathbf{x}\in\Bbb{R}^{t_a \times d_f}x∈Rta×df,并为每一个片段生成一个概率,概率表示片段是背景或者动作,px∈Rta\mathbf p_x \in\Bbb{R}^{t_a}px∈Rta。
px=σ(tconv(x)),tconv(x)=F(φ(F(x;W1));W2)(1)\mathbf p_x = \sigma(t_{conv}(\mathbf x)), t_{conv(\mathbf x)}=\mathcal{F}(\varphi(\mathcal{F}(\mathbf {x;W_1}));\mathbf {W_2}) \tag{1}
px=σ(tconv(x)),tconv(x)=F(φ(F(x;W1));W2)(1)
这里的F(.;W)\mathcal{F}(.;\mathbf W)F(.;W)表示一个卷积操作,W是卷积的权重。在为每个连续片段特征x\mathbf xx生成概率px\mathbf p_xpx之后,损失按批次内每个输入样本的交叉熵计算:
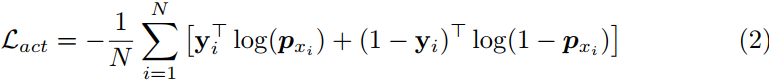
这里yi∈Rta\mathbf y_i\in\Bbb{R}^{t_a}yi∈Rta是每个输入xix_ixi的标签序列,如果片段包含动作则相应位置(label 1,反之 0);N是batch 大小。
Actionness proposal generation strategy. 根据TAG方法实现了分水岭算法来分割一维序列信号。鉴于每个片段的actionness得分,组成原始proposal的片段其分数都大于阈值τ\tauτ。对于一些相邻的原始proposal,如果相邻proposals总时间/总时间(proposals持续时间+中间的空白时间)的比例大于某个阈值η\etaη,则这些相邻的proposals和它们之间的空白空间被分为一组,形成一个的原始proposal。不断迭代η\etaη和τ\tauτ不同值的不同组合,并且应用非极大值抑制(NMS),最终输出actionness proposals {bj}\{{b_j}\}{bj}。 具体可参见SSN-TAG方法。
Sliding window sampling strategy.
不像actionness提名依赖于actionness分数分布,滑动窗口可以均匀覆盖视频中的所有片段。目标是最大限度地匹配groundtruth段(高召回率),同时尽可能地减少滑动窗口的数量。在的实验的验证集上测试了窗口大小和重叠比的不同组合。滑动窗口记作{ak}\{a_k\}{ak}。详细见论文第4.2节。
如前所述,actionness提名可能更精确但不太稳定,但滑动窗口提名更稳定但不太精确。第二阶段的目标是从滑动窗口提名再收集提名,这些提名可能被TAG方法忽略。
这个阶段的核心是一个二元分类器,它的输入是一系列片段特征序列(即一个提案),输出是TAG方法能否正确检测到该提案的概率。该分类器称为提名-级的动作性可信度估计器(Proposal-level Actionness Trustworthiness Estimator (PATE))。
PATE training.
训练样本采集,给定一个视频,其实例段{gi}\{g_i\}{gi}与actionness提名{bj}\{b_j\}{bj}匹配。对于一个实例段gig_igi,如果存在一个actionness提名bjb_jbj与gig_igi的tIoU大于阈值θc\theta_cθc,则标签gig_igi作为一个正样本(yi=1)(y_i=1)(yi=1);如果没有,则作为负样本(yi=0)(y_i=0)(yi=0)。将实例gig_igi时间内包含的片段级特征平均为一个proposal级特征xgi∈Rdf\mathbf x_{g_i}\in\Bbb{R}^{d_f}xgi∈Rdf。PATE输出的是利用TAG方法能检测到该proposal的可信度分数:
![]()
对每个批次的训练样本进行标准交叉熵损失训练(N为批次大小)
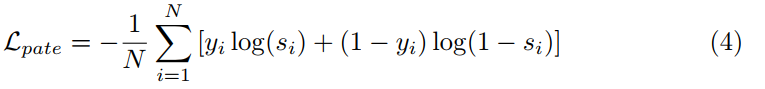
Complementary filtering.
这个评估器在训练的时候使用的TAG产生proposal来训练的,其特征也是片段-级的特征组成的。在测试时,只需要判断滑动窗口的proposal能否被TAG方法检测到,如果能检测到那就丢弃,反之收集起来。所以直接将滑动窗口的proposal作为输入,如果其判断分数低于阈值θa\theta_aθa,说明TAG方法可能检测不到这个段的proposal,将他收集起来。从滑动窗口收集的proposals与所有的actionness proposals合起来{cm}\{c_m\}{cm},作为下一阶段的输入。
有了候选的proposals,接下来就是对这些proposas进行边界调整和排名,** Temporal convolutional Adjustment and Ranking (TAR)** 用时间卷积层聚合片段级特征。
TAR Architecture.
如图2的后部分所示,这里输入的proposal表示为cmc_mcm,其开始结束边界表示为us,ueu_s,u_eus,ue。这里对三个部分进行特征聚合再提取:①对整个proposal的片段级特征采样nctln_{ctl}nctl出个片段特征作为新的特征xc∈Rnctl×df\mathbf x_c\in\Bbb{R}^{n_{ctl}\times d_f}xc∈Rnctl×df;②对proposal的开始边界扩充为[us−nctx/2,us+nctx/2][u_s-n_{ctx}/2,u_s+n_{ctx}/2][us−nctx/2,us+nctx/2],其特征维度xs∈Rnctx×df\mathbf x_s\in\Bbb{R}^{n_{ctx}\times d_f}xs∈Rnctx×df;③对proposal的结束边界扩充为[ue−nctx/2,ue+nctx/2][u_e-n_{ctx}/2,u_e+n_{ctx}/2][ue−nctx/2,ue+nctx/2],其特征维度xe∈Rnctx×df\mathbf x_e\in\Bbb{R}^{n_{ctx}\times d_f}xe∈Rnctx×df。
这三个特征序列(一个proposal序列和两个边界序列)被输入到三个独立的子网络中。Proposal ranking子网络输出动作概率,边界调整子网络输出回归补偿。每个子网络包含两个时间卷积层。
![]()
这里os,oe,pco_s,o_e,p_cos,oe,pc分别表示开始结束边界的偏移量的预测和动作概率。最终分数,来自滑窗的proposalaka_kak,其最终分数PATE分数乘以TAR分数(pt(ak)×pc(ak))(p_t(a_k)\times p_c(a_k))(pt(ak)×pc(ak));actionness proposals直接用pc(ak)p_c(a_k)pc(ak)。
TAR Training.
训练数据采集。用密集滑动窗口与动作实例匹配,一个滑动窗口被分配给一个groundtruth段,如果:(1)在所有其他窗口中,它与某个groundtruth段的重叠度最高;(2)与其中任何一个groundtruth片段的tIoU大于0.5。我们使用标准的Softmax交叉熵损失来训练 proposal ranking子网络,用L1\mathbf {L1}L1距离损失徐连边界调整子网络,回归损失可以表示为:
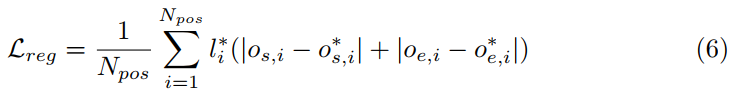
其中os,io_{s,i}os,i是预测的开始边界的偏移量,oe,io_{e,i}oe,i是预测的结束边界的偏移量,os,i∗o^*_{s,i}os,i∗是动作实例的开始边界的偏移量,oe,i∗o^*_{e,i}oe,i∗是动作实例的结束边界的偏移量。li∗l^*_{i}li∗是标签,1代表正样本。NposN_{pos}Npos是一个小批量的正样本数量,因为回归损失只计算正样本。
一些网络训练的细节可以看论文,
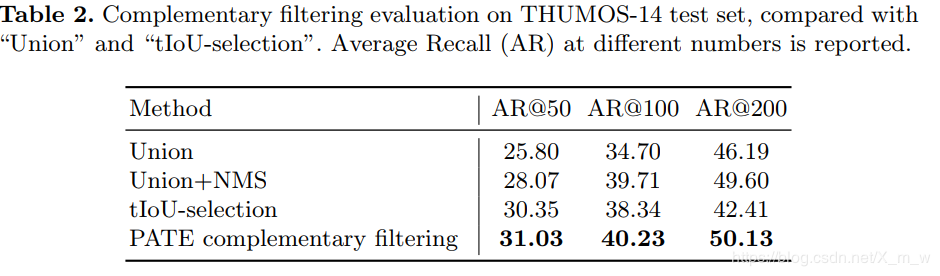
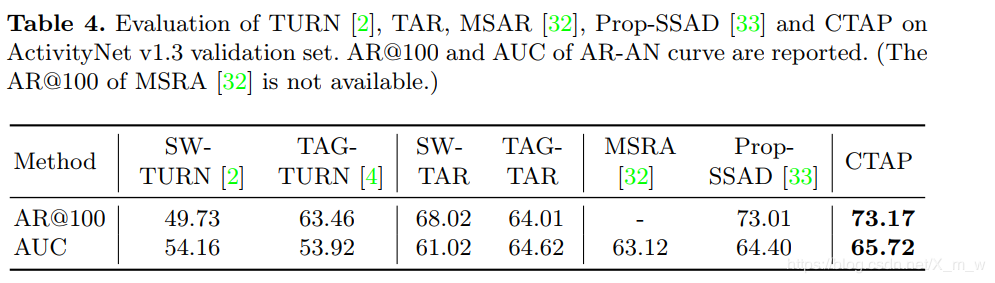
作者:X.mw